기계 학습의 모든 알고리즘은 "객관 함수"라고 하는 함수를 최소화하거나 최대화하는 데 의존합니다. 최소화된 함수 그룹을 "손실 함수"라고 합니다. 손실 함수는 예상 결과를 예측할 수 있다는 점에서 예측 모델이 얼마나 좋은지를 측정한 것입니다. 함수의 최소점을 찾는 가장 일반적으로 사용되는 방법은 "기울기 하강법"입니다. 기복이 있는 산과 같은 손실 함수를 생각하고 경사 하강법은 산 아래로 미끄러져 내려와 가장 아래 지점에 도달하는 것과 같습니다.
모든 종류의 데이터에 대해 작동하는 단일 손실 함수는 없습니다. 이는 이상값의 존재, 기계 학습 알고리즘의 선택, 경사 하강법의 시간 효율성, 도함수 찾기의 용이성 및 예측의 신뢰도를 비롯한 여러 요인에 따라 달라집니다. 이 블로그 시리즈의 목적은 다양한 손실과 각 손실이 데이터 과학자를 어떻게 도울 수 있는지 알아보는 것입니다.
손실 함수는 분류 및 회귀 손실의 두 가지 유형으로 크게 분류할 수 있습니다 . 이 게시물에서는 회귀 손실에 초점을 맞추고 있습니다. 향후 게시물에서는 다른 범주의 손실 함수를 다룹니다. 제가 놓친 부분이 있으면 댓글로 알려주세요. 또한 이 블로그에 표시된 모든 코드와 플롯은 이 노트북에서 찾을 수 있습니다.
Mean Square Error(MSE) 는 가장 일반적으로 사용되는 회귀 손실 함수입니다. MSE는 목표 변수와 예측 값 사이의 제곱 거리의 합입니다.
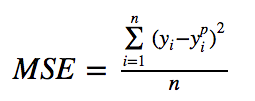
아래는 실제 목표 값이 100이고 예측 값 범위가 -10,000에서 10,000 사이인 MSE 함수의 플롯입니다. MSE 손실(Y축)은 예측(X축) = 100에서 최소값에 도달합니다. 범위는 0에서 ∞입니다.
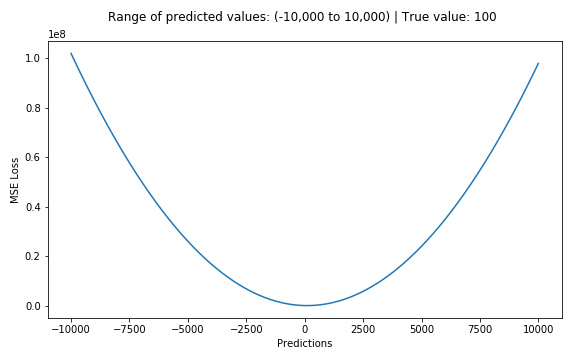
MSE 손실 도표(Y축) 대 예측(X축)
Mean Absolute Error (MAE)는 회귀 모델에 사용되는 또 다른 손실 함수입니다. MAE는 목표 변수와 예측 변수 간의 절대 차이의 합입니다. 따라서 방향을 고려하지 않고 일련의 예측에서 오류의 평균 크기를 측정합니다. (또한 방향을 고려하면 잔차/오차의 합인 Mean Bias Error(MBE)라고 합니다.) 범위도 0~∞입니다.
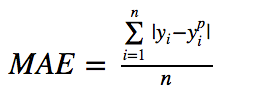
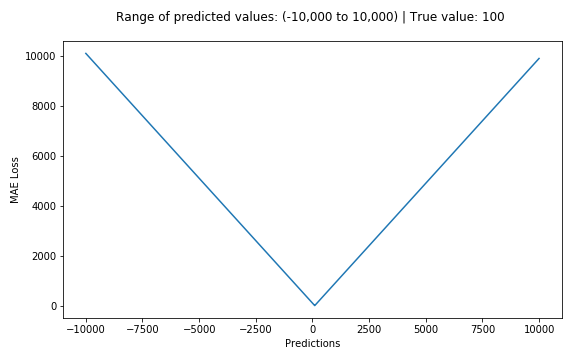
MAE 손실 플롯(Y축) 대 예측(X축)
요컨대, 제곱 오차를 사용하는 것이 해결하기 더 쉽지만 절대 오차를 사용하는 것이 이상값에 더 강력합니다. 그러나 그 이유를 이해합시다!