
기본적으로 convolution layer는 fully connected layer에서 spatial(이미지의 가로세로) 영역을 잘게 쪼개고, 그만큼 weight sharing을 시킨 아키텍쳐이다.
그러나 feature dimension(=channel, depth)에 대해서는 여전히 fully connected를 유지하고 있다. 즉 모든 input channel을 섞어서 각각의 output channel로 연결하는 과정이 fully connected라는 의미이다. 수식으로 말하자면 input channel이 256 dim이고 output channel이 128 dim이라면, feature dim에 대한 weight matrix는 [256x128]로 fully connected 이다.
속칭 그룹 convolution은 아주 간단히말해 input channel을 N등분 시켜서 group단위로 channel을 쪼개고, 그 group 대해서 각각 일반 convolution을 한 것이다.
쉽게 말하면 위의 예시에서 2개의 group을 가진 grouped convolution을 적용하면, input과 output channel을 2개의 그룹으로 나누고, 각각에 대해 [128x64]의 weight matrix를 구하는 것이다. 즉 feature dim에 대해 fully connected가 아닌 쪼개진 convolution을 하겠다는 것이다.
한줄로 말하면 위의 Grouped Convolution에서 group의 개수를 input channel의 개수만큼 만들겠다는 것이다. 즉 1개의 group에 1개의 channel만 들어가 있다. 즉 input channel이 RGB였다면, R에 해당하는 정보만 보는 convolution, G만 보는 convolution, B만 보는 convolution을 만들겠다는 것이다. 이렇게하면 항상 output channel의 개수는 input channel과 같을 수 밖에 없다. 이 방식은 서로 다른 feature를 섞지 않지만, 대신 spatial로만 정보를 섞겠다는 의미이다. 즉 Red channel의 정보를 3x3의 픽셀에 대해서 고려하겠다라는 의미이다. 이러한 아키텍쳐는 point-wise convolution(1x1 convolution)과 같이 등장하는 경우가 많으며, 각각 역할을 분리하여 하나는 spatial 정보만 섞고, 하나는 feature dim에대한 정보만 섞는 역할을 하게 된다. 이러한 것을 통칭해 seperable convolution이라고도 한다.
앞에서 등장한 depth-wise convolution이 오직 spatial dimension의 정보만 섞었다라면, 이번에는 반대로 spatial dimension의 정보는 섞지 않고 오직 channel dimension의 정보만 섞는 아키텍쳐가 바로 point-wise convolution이다. 이에 대한 구현은 아주 간단하게 2d conv의 kernel size를 (1, 1)로 넣으면 되기 때문에 1x1 convolution이란 이름으로도 널리 불린다. 즉 공간적인 의미의 고려 없이 오직 feature dim에 대해서만 fully connected를 수행하는 아키텍쳐라고 볼 수 있다.
앞에서도 살짝 언급되었지만, 일반적인 convolution이 spatial과 channel의 정보를 한 번에 뒤섞는 아키텍쳐라면 depth-wise seperable convolution은 이 두가지를 완전히 분리하여 처리하는 아키텍쳐를 의미한다. 그래서 일단 이미지가 들어오면 먼저 spatial정보만 섞는 depth-wise convolution을 일단 수행하고, 그렇게 나온 feature에 point-wise convolution을 수행하여 이번에는 channel정보에 대해서 섞겠다는 의미이다.
이렇게 두가지를 완전히 분리할 경우, 기존의 일반 convolution에 훨씬 더 적은 연산량과 파라미터로 유사한 기능을 수행 할 수 있다. 그리고 이는 더 적은 overfitting을 가지므로 더 높은 성능을 낸다.
Depth-wise Separable Convolution
Depth-wise separable Convolution을 가장 잘 표현한 그림이라고 생각합니다.
하지만 CNN에 대해 자세한 이해가 없으면 이 그림을 보더라도 이해가 잘 가지 않습니다.
위 그림을 이해하기 위해서는 Standard(일반) Convolution을 정확히 파악해야 합니다.
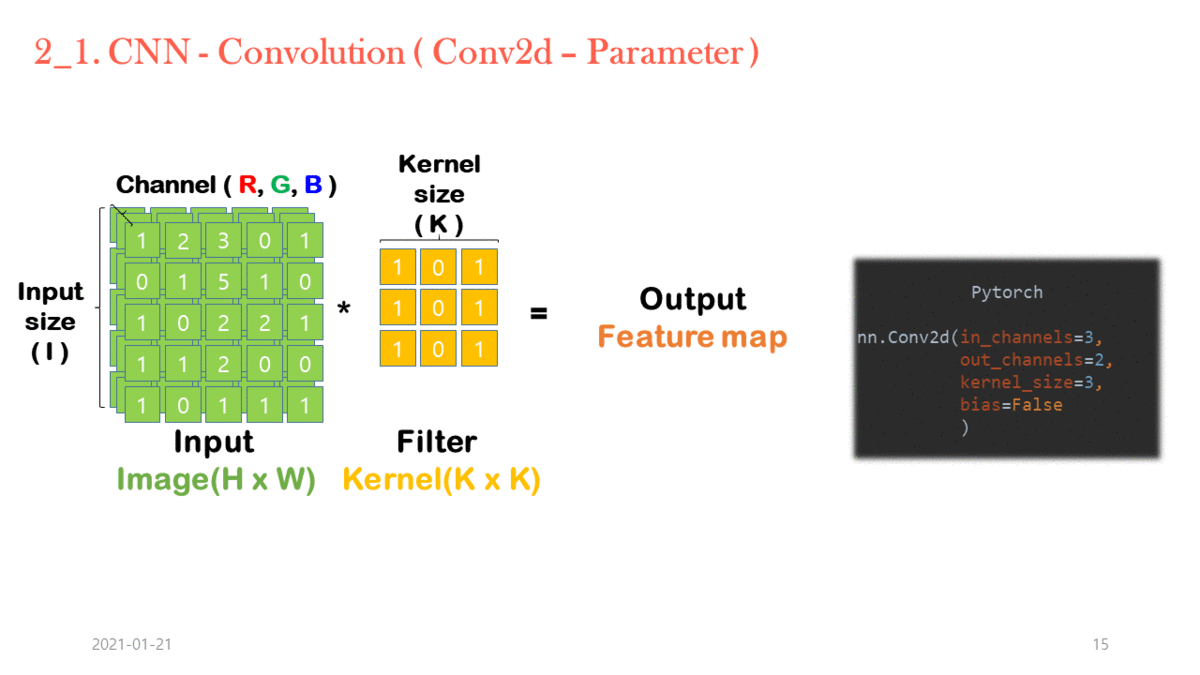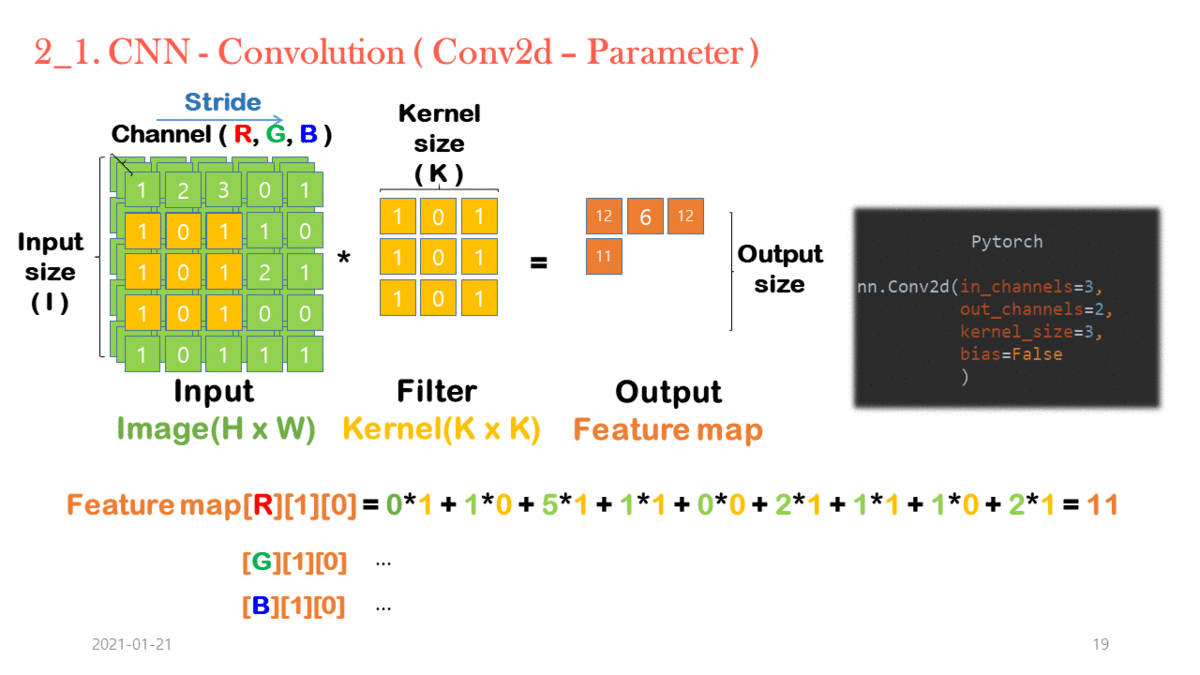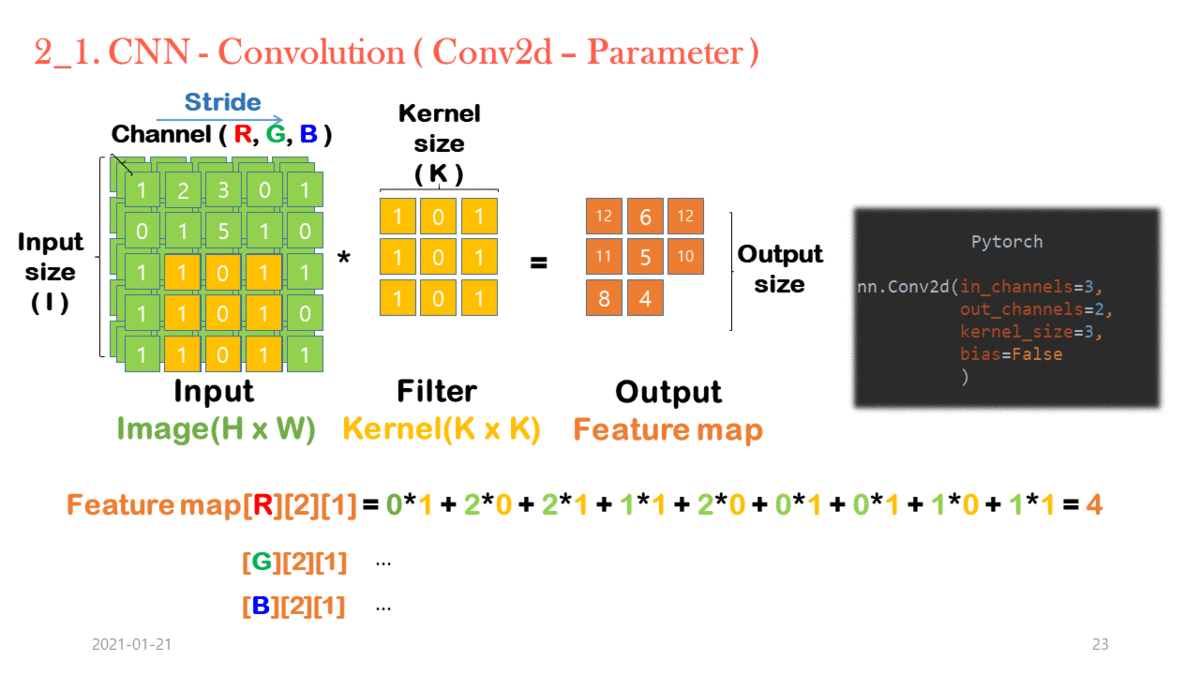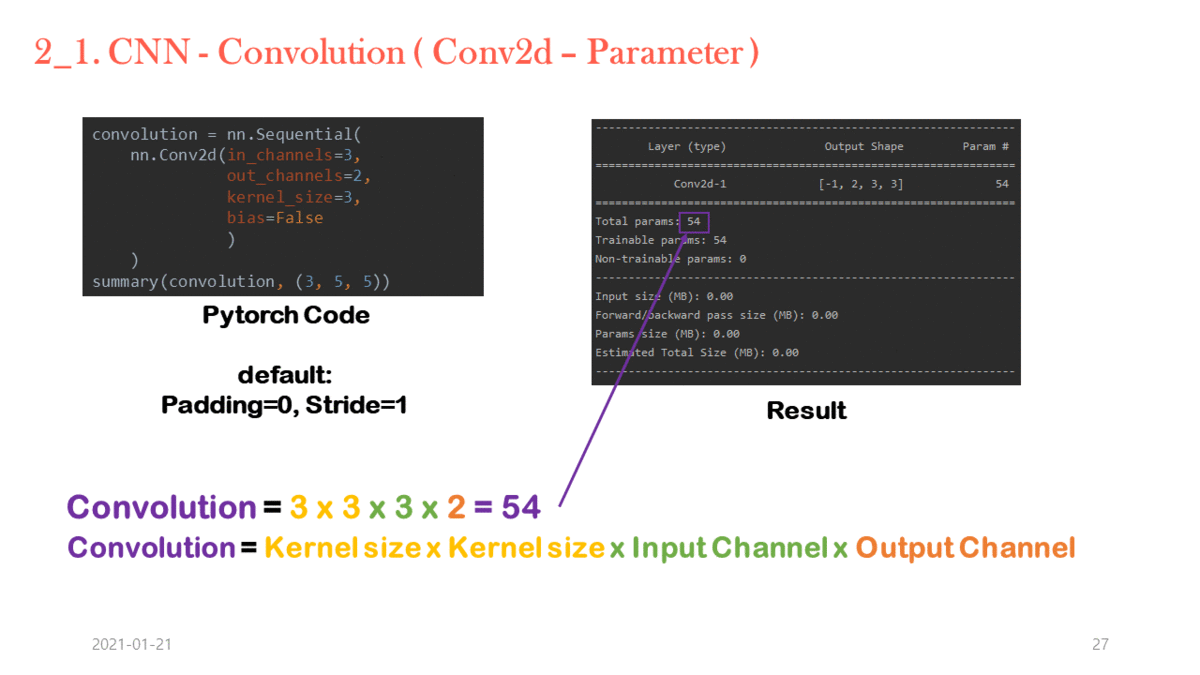
Standard Convolution 연산 과정